技術分享:Linux多核并行編程關鍵技術
發部時間段:2018-09-20 11:28:00
多核串行程序語言的環境
在摩爾運動熱力學定律不能正常工作在之前,加強加工處里設備效能按照主頻加強、電腦硬件超線程等技術工藝就能符合利用所需。隨著時間的推移主頻加強通過生活緩慢快要撞上音速這道墻,摩爾運動熱力學定律剛剛開始越來越不能正常工作,多核集變成 加工處里設備效能加強的進步動向方法手段。現下世上面己經就很難看過單核心的加工處里設備,也是這樣進步動向的旁證。要寬裕充分展現多核豐富性的換算市場勝機,多核下的串行程序編寫就沒法以免,Linux kernel也是一主要的多核串行程序編寫消費場景。但多核下的串行程序編寫卻的挑戰多進行。
多核串行程序(xu)編程的挑釁(xin)
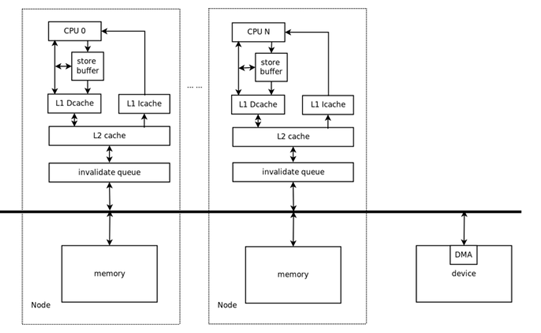
當今流行的算公式機全是馮諾依曼指標體系結構,即共享服務運存的算公式繪圖,這類歷程算公式繪圖對并行算起算公式并不友善。如圖是種主要表現的算公式機操作系統指標體系指標體系結構。